
Part I: SELECT SINGLE vs FOR ALL ENTRIES
Part II: SELECT SINGLE vs FOR ALL ENTRIES, secondary index access
When all business requirements are met in a development, customer complaints always come down to performance. “Can’t this run any faster?” we always hear. Performance, in a technical point of view, is a broader concept that not just includes execution time, but also optimal use of system resources like memory and network load. But powerful hardware of our age and requirement of end user satisfaction leaves us with a single option to have execution time (or speed) as the top priority performance aspect. So I will experiment on some known techniques for database access and internal table processing, and share the results here.
I will use the table DD03L (data dictionary table for table fields) for our experiment. It is available on every SAP system and it has over 6.000.000 (six million) records even in a freshly installed ECC system.
Execution time comparison of SELECT SINGLE in LOOP versus SELECT … FOR ALL ENTRIES and READ TABLE in LOOP
Answer might be obvious for some of you but let’s see the real impact on execution time. Here is our scenario:
- Data set quantity is 100.000 (hundred thousand) records. I think this is a fair and realistic amount.
- We can access search table with primary key.
- We know we won’t come across same search key second time. This might be possible according to business requirement.
SELECT SINGLE in LOOP
Below program simply selects some data set from table DD03L, loops through it and searches database table with SELECT SINGLE . I will run this program three times, for data sets from the beginning, from the middle and near the end of database table.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
CLASS lcl_controller DEFINITION. PUBLIC SECTION. DATA t_driver TYPE TABLE OF dd03l. METHODS: retrieve_test_data IMPORTING ip_first TYPE i ip_last TYPE i, search. ENDCLASS. CLASS lcl_controller IMPLEMENTATION. METHOD retrieve_test_data. DATA ls_dd03l TYPE dd03l. SELECT * FROM dd03l INTO ls_dd03l. IF sy-dbcnt BETWEEN ip_first AND ip_last. APPEND ls_dd03l TO me->t_driver. ENDIF. IF sy-dbcnt = ip_last. EXIT. ENDIF. ENDSELECT. ENDMETHOD. METHOD search. DATA: ls_driver LIKE LINE OF me->t_driver, ls_dd03l TYPE dd03l. LOOP AT me->t_driver INTO ls_driver. SELECT SINGLE * FROM dd03l INTO ls_dd03l WHERE tabname = ls_driver-tabname AND fieldname = ls_driver-fieldname AND as4local = ls_driver-as4local AND as4vers = ls_driver-as4vers AND position = ls_driver-position. ENDLOOP. ENDMETHOD. ENDCLASS. DATA go_experiment TYPE REF TO lcl_controller. START-OF-SELECTION. CREATE OBJECT go_experiment. *-Get 100.000 records as a test set go_experiment->retrieve_test_data( ip_first = 1 ip_last = 100000 ). *-Loop through driver table and search in database go_experiment->search( ). |
Let’s run this program with transaction SAT and observe the gross runtime of our search method.
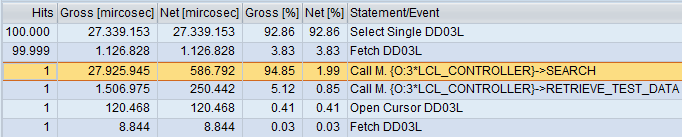


We can see that placement of data in database table does not impact much. This might be because of the search algorithm of database system.
SELECT … FOR ALL ENTRIES and READ TABLE in LOOP
Below program is pretty much like the previous one but this time we select the result set with FOR ALL ENTRIES and search on the internal table with READ TABLE in LOOP . Note that we are using a hashed table for our search table because according to official performance tips and tricks (see transaction SAT):
Hashed tables are optimized for single entry access
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
CLASS lcl_controller DEFINITION. PUBLIC SECTION. DATA t_driver TYPE TABLE OF dd03l. METHODS: retrieve_test_data IMPORTING ip_first TYPE i ip_last TYPE i, search. ENDCLASS. CLASS lcl_controller IMPLEMENTATION. METHOD retrieve_test_data. DATA ls_dd03l TYPE dd03l. SELECT * FROM dd03l INTO ls_dd03l. IF sy-dbcnt BETWEEN ip_first AND ip_last. APPEND ls_dd03l TO me->t_driver. ENDIF. IF sy-dbcnt = ip_last. EXIT. ENDIF. ENDSELECT. ENDMETHOD. METHOD search. DATA: lt_result TYPE HASHED TABLE OF dd03l WITH UNIQUE KEY tabname fieldname as4local as4vers position, ls_driver LIKE LINE OF me->t_driver. SELECT * FROM dd03l INTO TABLE lt_result FOR ALL ENTRIES IN me->t_driver WHERE tabname = me->t_driver-tabname AND fieldname = me->t_driver-fieldname AND as4local = me->t_driver-as4local AND as4vers = me->t_driver-as4vers AND position = me->t_driver-position ORDER BY PRIMARY KEY. LOOP AT me->t_driver INTO ls_driver. READ TABLE lt_result TRANSPORTING NO FIELDS WITH TABLE KEY tabname = ls_driver-tabname fieldname = ls_driver-fieldname as4local = ls_driver-as4local as4vers = ls_driver-as4vers position = ls_driver-position. ENDLOOP. ENDMETHOD. ENDCLASS. DATA go_experiment TYPE REF TO lcl_controller. START-OF-SELECTION. CREATE OBJECT go_experiment. *-Get 100.000 records as a test set go_experiment->retrieve_test_data( ip_first = 1 ip_last = 100000 ). *-Select matching records with FOR ALL ENTRIES *-Loop through driver table and search in hashed table go_experiment->search( ). |
After running three times:
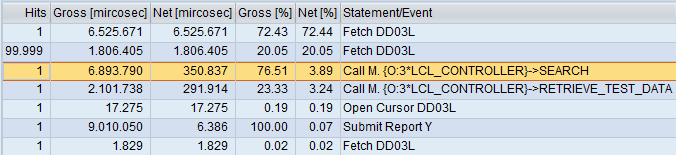


Conclusion
We can see that difference is significant. If we are accessing search table with primary key, we can safely prefer FOR ALL ENTRIES and READ TABLE over SELECT SINGLE in LOOP although the latter is more convenient to implement. But we must beware two common pitfalls:
- Using FOR ALL ENTRIES with empty driver table, which will result in fetching all records from database table.
- Using sequential search on large internal tables, which will result in significantly slower search compared to binary search and hash algorithm.