
Part I: SELECT SINGLE vs FOR ALL ENTRIES
Part II: SELECT SINGLE vs FOR ALL ENTRIES, secondary index access
I believe our previous test on SELECT SINGLE vs FOR ALL ENTRIES did not surprise many of you because I see a tendency towards FOR ALL ENTRIES in programs I encounter. In previous scenario, we were able to access the search table with primary key but this may not be the case every time. Let’s see what happens if we could not access the search table with primary key, but with secondary index.
Execution time comparison of SELECT SINGLE in LOOP versus SELECT … FOR ALL ENTRIES and READ TABLE in LOOP, with secondary index
Our scenario differs a little from previous test:
- Data set quantity is just 500 records because we are not accessing with primary key, otherwise we might have to wait a while to run the tests.
- Our access key corresponds to a secondary index of database table.
- We assume we won’t come across same search key second time.
SELECT SINGLE in LOOP
Below program simply selects some data set from table DD03L, loops through it and searches database table with SELECT SINGLE. I will run this program one time for 100.000 (hundred thousand) records to compare execution time with previous test, and three times for 500 records to compare with FOR ALL ENTRIES test, again for data sets from the beginning, from the middle and near the end of database table.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
CLASS lcl_controller DEFINITION. PUBLIC SECTION. DATA t_driver TYPE TABLE OF dd03l. METHODS: retrieve_test_data IMPORTING ip_first TYPE i ip_last TYPE i, search. ENDCLASS. CLASS lcl_controller IMPLEMENTATION. METHOD retrieve_test_data. DATA ls_dd03l TYPE dd03l. SELECT * FROM dd03l INTO ls_dd03l. IF sy-dbcnt BETWEEN ip_first AND ip_last. APPEND ls_dd03l TO me->t_driver. ENDIF. IF sy-dbcnt = ip_last. EXIT. ENDIF. ENDSELECT. ENDMETHOD. METHOD search. DATA: ls_driver LIKE LINE OF me->t_driver, ls_dd03l TYPE dd03l. LOOP AT t_driver INTO ls_driver. SELECT SINGLE * FROM dd03l INTO ls_dd03l WHERE rollname = ls_driver-rollname AND as4local = ls_driver-as4local. ENDLOOP. ENDMETHOD. ENDCLASS. DATA go_experiment TYPE REF TO lcl_controller. START-OF-SELECTION. CREATE OBJECT go_experiment. *-Get 500 records from the middle of table as a test set go_experiment->retrieve_test_data( ip_first = 1 ip_last = 500 ). *-Loop through driver table and search in database go_experiment->search( ). |
First, execution time result for hundred thousand records:

It seems that performance difference is notable for primary key access against secondary index access. Let’s see execution time results for 500 records from the beginning, middle and the end of the table:



That is blazing fast. 500 SELECT SINGLEs take almost no time with secondary index access (and most probably with primary key access).
SELECT … FOR ALL ENTRIES and READ TABLE in LOOP
Below program is pretty much like the previous one but this time we select the result set with FOR ALL ENTRIES and search on the internal table with READ TABLE in LOOP. This time we don’t use a hashed table because we can’t exactly be sure that our search key is unique.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
CLASS lcl_controller DEFINITION. PUBLIC SECTION. DATA t_driver TYPE TABLE OF dd03l. METHODS: retrieve_test_data IMPORTING ip_first TYPE i ip_last TYPE i, search. ENDCLASS. CLASS lcl_controller IMPLEMENTATION. METHOD retrieve_test_data. DATA ls_dd03l TYPE dd03l. SELECT * FROM dd03l INTO ls_dd03l. IF sy-dbcnt BETWEEN ip_first AND ip_last. APPEND ls_dd03l TO me->t_driver. ENDIF. IF sy-dbcnt = ip_last. EXIT. ENDIF. ENDSELECT. ENDMETHOD. METHOD search. DATA: lt_result TYPE STANDARD TABLE OF dd03l, ls_driver LIKE LINE OF me->t_driver. SELECT * FROM dd03l INTO TABLE lt_result FOR ALL ENTRIES IN me->t_driver WHERE rollname = me->t_driver-rollname AND as4local = me->t_driver-as4local. SORT lt_result BY fieldname as4local. LOOP AT me->t_driver INTO ls_driver. READ TABLE lt_result TRANSPORTING NO FIELDS WITH KEY checktable = ls_driver-rollname as4local = ls_driver-as4local BINARY SEARCH. ENDLOOP. ENDMETHOD. ENDCLASS. DATA go_experiment TYPE REF TO lcl_controller. START-OF-SELECTION. CREATE OBJECT go_experiment. *-Get 500 records from the middle of table as a test set go_experiment->retrieve_test_data( ip_first = 1 ip_last = 500 ). *-Select matching records with FOR ALL ENTRIES *-Loop through driver table and search in internal table with binary search go_experiment->search( ). |
After running three times:
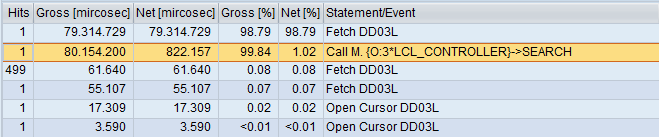
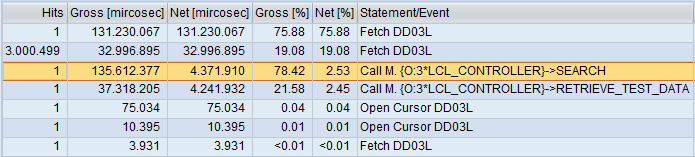
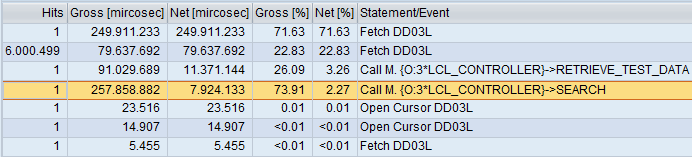
Result is somewhat surprising. Previous test’s winner is big time loser of this test. Plus the placement of data also causes a difference. This might well be because of the data retrieval routine but result is still decisive.
Conclusion
This test tells us that we should not use FOR ALL ENTRIES with a non-primary key access. It has a significant processing time even with a record count as low as 500.